A sighly more complex data app¶
In this example, we’ll introduce you to a more advanced use of bauplan SDK. We will build a data exploration app that provides a web UI to:
navigate across the branches and the tables of the data catalog
inspect the tables’ schemas
run interactive queries in a simple SQL editor
Since one of the design principles of bauplan is that every core operation of the platform can always be embedded in the code of another application, we are going to use this example to illustrate further how to use the Python SDK. In particular, we will explore methods to interact with the core functionalities of the data catalog and the runtime simultaneously.
Set up¶
We will use Streamlit for our app. Go into
examples/02-data-catalog-app, create a virtual environment, install
the necessary requirements and then run the app:
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
streamlit run exploration_app.py
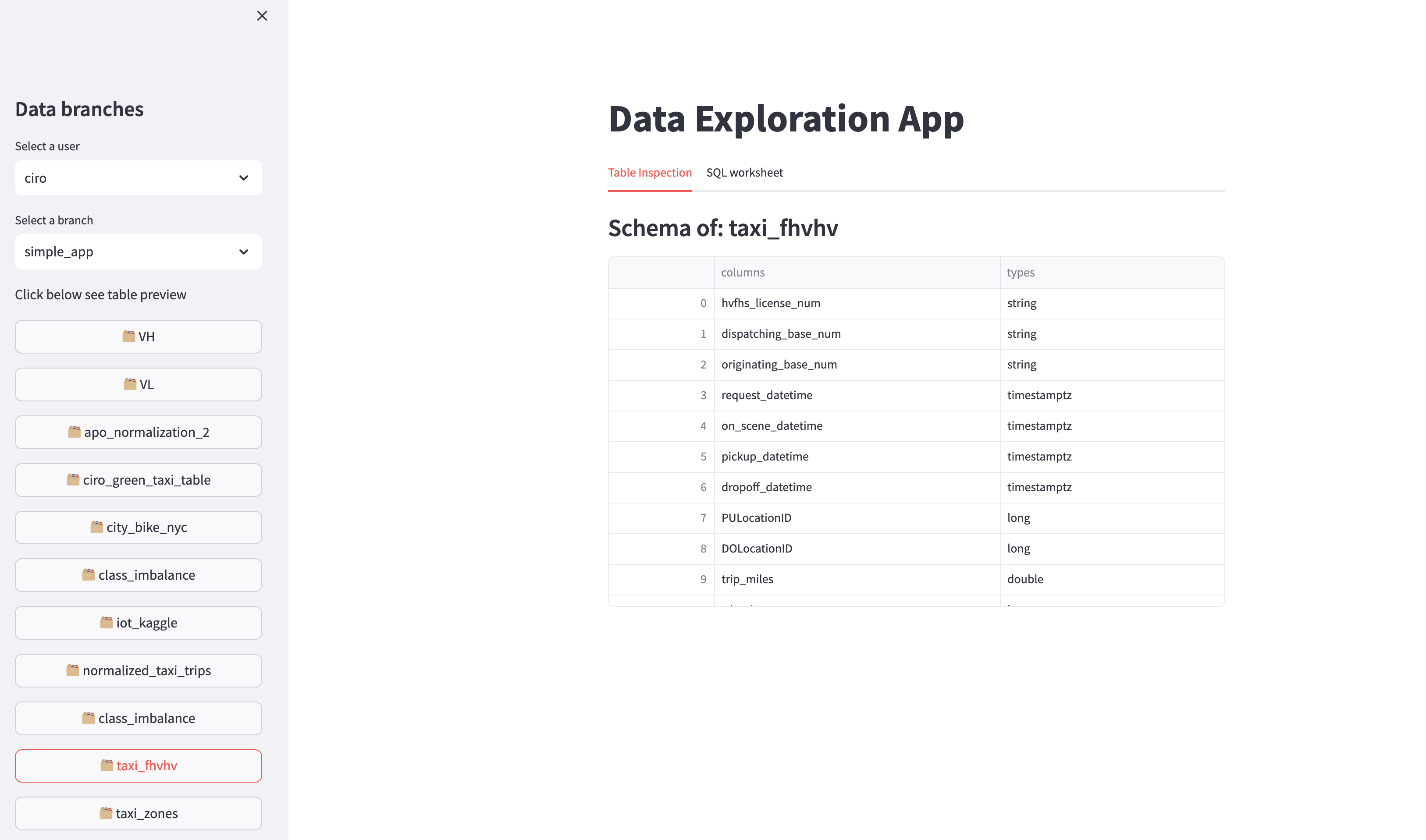
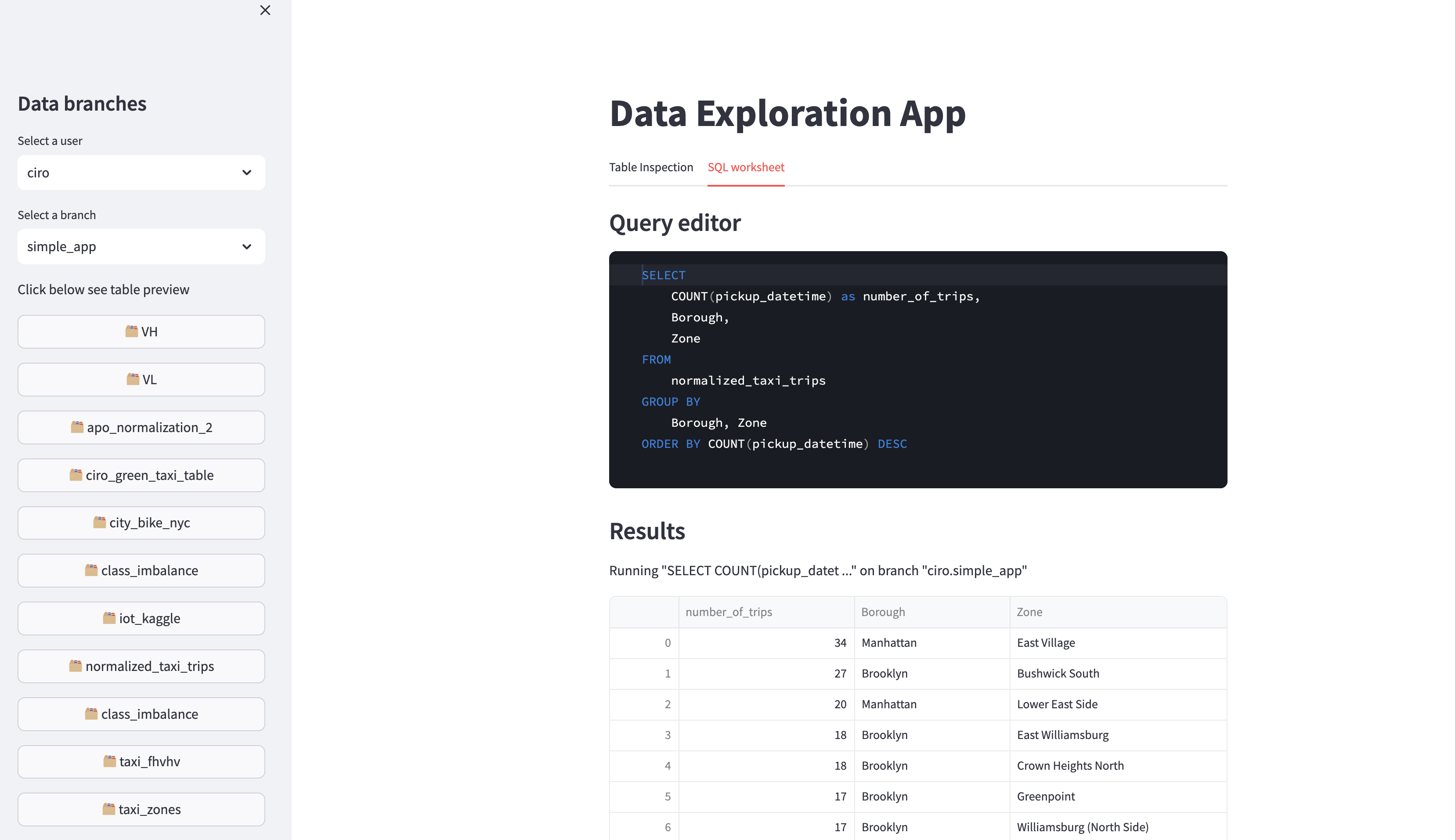
This app is composed by three main elements:
a dropdown menu on the left sidebar that allows the user to pick a specific branch in the catalog,
a table inspection tab to quickly preview the schema of the selected tables,
a SQL worksheet where the user can input arbitrary SQL and run interactive queries against the data in the data catalog.
More SDK methods to program with bauplan¶
As it is easy to see from the code of the app, all these three elements
make use of the bauplan SDK. We already know the client method
client.query(...).to_pandas which allows to run a SQL query and return the
results as a Pandas DataFrame. In this app we use this method to run interactive queries against any table with the SQL worksheet.
import bauplan
client = bauplan.Client()
# general description of the behavior:
# run a query against an arbtrary branch and return the results as a Pandas DataFrame
df = client.query('SELECT c1 FROM my_table', branch_name='my_branch').to_pandas()
The catalog methods from bauplan.Client allow us to manipulate the data
catalog. For example, get_branches gets all the available data
branches in the bauplan catalog as a list of branches, each having
name, hash, data_name. So for instance, if we wanted to have
all the branch names in our catalog we could use this method like this:
import bauplan
client = bauplan.Client()
branch_names = [branch.name for branch in client.get_branches()]
It is easy to see that this method is equivalent of
bauplan branch in the CLI. In the app, we use get_branches to
construct the drop down on the left.
The method get_branch , instead, takes a branch as an argument and
gets all the existing tables in that branch - which is the equivalent of
the CLI command bauplan branch get <BRANCH_NAME>.
import bauplan
client = bauplan.Client()
# retrieve only the tables as tuples of (name, kind)
tables = [(b.name, b.kind) for b in client.get_branch('my_branch')]
In the app, we use get_branch to retrieve the tables from the branch selected in the drop down menu.
Finally, get_table takes a branch and a table as arguments, and
retrieves the fields and metadata for that table in that branch. For
instance:
import bauplan
client = bauplan.Client()
# get the fields and metadata for the table named 'taxi_zones'
# in the main branch
table_schema = client.get_table(branch_name='main', table_name='taxi_zones')
# loop through the fields and print their name, required, and type
for c in table_schema:
print(c.name, c.required, c.type)
In the app, we use get_table to retrieve the table schema visualized in the Table Inspection Tab.
Below is the entire code of the Streamlit app. The code is heavily commented, we leave it as an exercise to the reader to explore how the SDK methods were used to implement the various functionalities of the app.
import streamlit as st
import pandas as pd
from code_editor import code_editor
# we import the bauplan Python SDK, with pre-built functions
# these functions allow us to access bauplan catalog APIs and retrieve all the active branches,
# the tables comprising a branch and the schema of a certain table in a certain branch
import bauplan
client = bauplan.Client()
# Function to query data and return as DataFrame
@st.cache_data()
def query_as_dataframe(
sql: str,
branch:str
):
"""
this function simply wraps the bauplan method query
and handles errors
"""
try:
return client.query(sql, branch_name=branch, args={'preview': 'True'})
except bauplan.exceptions.ResourceNotFoundError:
return None, 'Are you sure the table exists in the branch?'
def get_table_names(branch: str):
"""
this function wraps the get_branch method from bauplan SDK
to return a list of table names
"""
return [table.name for table in get_tables(branch)]
# Function to get well-formatted branches
def format_branches():
"""
formats the names of the branches to handle branches with a special syntax like 'main'
"""
branches = [branch.name for branch in client.get_branches()]
return [_b for _b in branches if len(_b.split('.')) == 2 or _b.split('.')[0] == 'main']
# Function to get users and their branches
def get_user_branches(branches: list):
"""
extract the branches corresponding to usernames from all the branches in the catalog
"""
users = {branch.split('.')[0] for branch in branches}
user_branches = [
{user: [branch.split('.')[1] for branch in branches if branch.split('.')[0] == user]}
if user != 'main' else {'main': 'main'}
for user in users
]
return user_branches
def schema_preview(
branch: str,
table: str,
namespace: str = 'bauplan'
):
"""
wrap the method get_table to return a table inspection and handle errors
"""
table_name = f'{namespace}.{table}'
try:
metadata = client.get_table_with_metadata(branch, table_name)
return pd.DataFrame({
'columns': [column.name for column in metadata.fields],
'types': [column.type for column in metadata.fields]
})
except bauplan.exceptions.BauplanError as e:
st.error(f"Error: {e.args[0]}")
return None
def query_and_display(
sql: str,
branch: str
):
"""
wrap query_as_dataframe and display the results in Streamlit
"""
# this returns a Pandas dataframe
result = query_as_dataframe(sql, branch)
if isinstance(result, pd.DataFrame):
st.dataframe(result, width=100000)
return result
else:
st.markdown(result[1])
return None
### STREAMLIT APP BEGINS HERE
def main():
import streamlit as st
st.markdown("# Data Exploration App")
# get branches and users
branches = format_branches()
user_branches = get_user_branches(branches)
users = sorted([key for d in user_branches for key in d.keys()])
# define the sidebar with the drop-down menu for picking users and branches
st.sidebar.markdown('# Data branches')
selected_user = st.sidebar.selectbox("Select a user", ['None'] + users, key=1)
# define the tabs of the app
table_inspection, sql_worksheet = st.tabs(["Table Inspection", "SQL worksheet"])
if selected_user == 'None':
st.markdown("Please, select a user on the left to begin")
st.stop()
if selected_user == 'main':
selected_branch = 'main'
else:
drop_down_branches = next((d[selected_user] for d in user_branches if selected_user in d), None)
selected_branch = st.sidebar.selectbox("Select a branch", ['None'] + drop_down_branches, key=2)
if selected_branch == 'None':
st.markdown(f"Hi {selected_user}. Please, select a branch on the left.")
st.stop()
selected_branch = f"{selected_user}.{selected_branch}"
table_names = get_table_names(selected_branch)
st.sidebar.write("Click below to see table preview")
with table_inspection:
for idx, table in enumerate(table_names, start=3):
if st.sidebar.button(f"🗂️ {table}", use_container_width=True, key=idx):
table_inspection = schema_preview(selected_branch, table)
st.markdown(f"### Schema of: {table}")
st.dataframe(table_inspection, width=1200)
with sql_worksheet:
st.markdown('### Query editor')
theme = "dark"
custom_btns = [
{
"name": "Run",
"feather": "Play",
"primary": True,
"hasText": True,
"showWithIcon": True,
"commands": ["submit"],
"style": {"bottom": "0.44rem", "right": "0.4rem"}
}
]
response_dict = code_editor('', lang='sql', height=[10, 20], theme=theme, buttons=custom_btns)
if response_dict['id'] and response_dict['type'] == "submit":
st.markdown('### Results')
query = response_dict['text'].strip()
if query:
q_string = f'{query[:30]} ...' if len(query) > 30 else query
st.write(f'Running "{q_string}" on branch "{selected_branch}"')
results = query_and_display(query, selected_branch)
if results is not None:
export = results.to_csv()
st.download_button(label="Download Results", data=export, file_name="query_results.csv")
else:
st.markdown('No query to run. Please write a query and press Run.')
st.stop()
if __name__ == "__main__":
main()
Summary¶
In this chapter, we demonstrated how to build a data exploration app using bauplan SDK and Streamlit. The app enables users to:
Navigate data branches
Inspect table schemas
Execute SQL queries interactively
This example highlights bauplan’s design principle of embedding core platform operations into other applications, showcasing the flexibility and programmability of the bauplan Python SDK.